- 1. Зачищенный контент
- 2. Синдицированный контент
- 3. HTTP и HTTPS страницы
- 4. WWW и не WWW страницы
- 5. Динамически генерируемые параметры URL
- 6. Подобный контент
- 7. Страницы для печати
- Последние мысли

Автор: Олег Барысевич
17 января 2017 г.

Дублированный контент - большая тема в сфере SEO. Когда мы слышим об этом, это в основном в контексте штрафов Google; но этот потенциальный побочный эффект дублирования контента не только взорван по важности (Google практически нет штрафует сайты за дублированный контент как таковой), но также вряд ли самое серьезное последствие проблемы. 3 наиболее вероятные проблемы SEO, которые могут быть вызваны дублирующимся контентом:
- Потраченный впустую бюджет. Если на вашем сайте внутреннее дублирование контента, то вы гарантированно отправите часть своего бюджета на сканирование (то есть количество поисковых страниц, которые сканируют поисковые системы за единицу времени) впустую. Это означает, что важные страницы на вашем сайте будут сканироваться реже.
- Ссылка для разбавления сока. Как для внешнего, так и для внутреннего дублирования контента, разбавление ссылочного сока является одним из самых больших недостатков SEO. Со временем оба URL-адреса могут создавать обратные ссылки, указывающие на них, и если один из них не имеет канонической ссылки (или перенаправления 301), указывающей на оригинальный фрагмент, ценные ссылки, которые помогли бы рангу исходной страницы выше, распределяются между обоими. URL-адрес.
- Только одна из страниц рейтинга по целевым ключевым словам. Когда Google находит дублированные экземпляры контента, он обычно показывает только один из них в ответ на поисковые запросы - и нет никакой гарантии, что это будет тот, который вы хотите ранжировать.
Но все эти сценарии можно предотвратить, если вы знаете, где может скрываться дублированный контент, как его обнаружить и как с ним бороться. В этой статье я собираюсь обрисовать в общих чертах 7 типов дублирования контента - и как справиться с каждым.
1. Зачищенный контент
Соскребенный контент - это, по сути, неоригинальная часть контента на сайте, которая была скопирована с другого сайта без разрешения. Как я уже говорил ранее, Google не всегда может различить оригинал и копию, поэтому владельцу сайта часто приходится следить за скребками и знать, что делать, если их контент украден.
Увы, это не всегда легко и просто. Но вот небольшая хитрость, которую я лично использую.
Если вы отслеживаете, как ваш контент распределяется и связывается с сетью (и если у вас есть блог, вы действительно должны это делать) через приложение для мониторинга социальных сетей и Интернета, например Awario Вы можете поразить двух зайцев одним выстрелом. В вашем инструменте мониторинга вы обычно используете URL-адрес и заголовок вашего сообщения в качестве ключевых слов в вашем предупреждении. Чтобы также искать очищенные версии вашего контента, все, что вам нужно сделать, это добавить еще одно ключевое слово - выдержку из вашего поста. В идеале, оно должно быть довольно длинным, например, предложение или два. Окружите кусок двойными кавычками, чтобы убедиться, что вы ищете точное совпадение. Это будет выглядеть так:
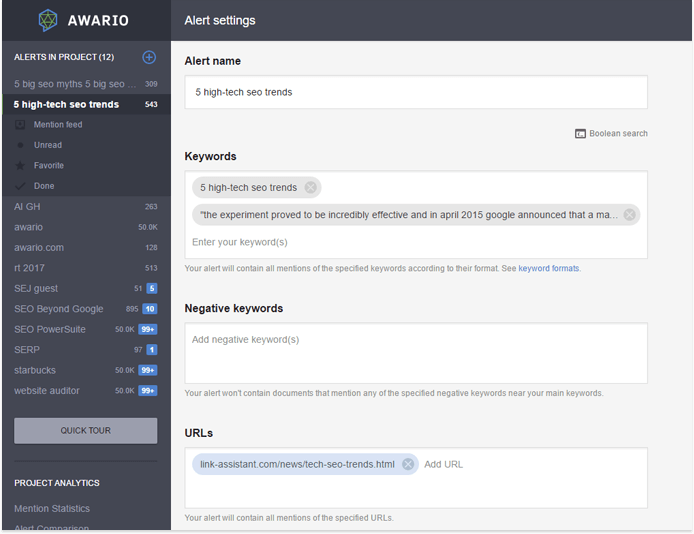
При такой настройке приложение будет искать как упоминания вашей оригинальной статьи (например, публикации, ссылки и т. Д.), Так и очищенные версии контента, найденного на других сайтах.
Если вы обнаружите скопированные копии своего контента, рекомендуется сначала связаться с веб-мастером и попросить его удалить этот фрагмент (или поставить каноническую ссылку на оригинал, если он вам подходит). Если это не эффективно, вы можете сообщить о скребке с помощью Google отчет о нарушении авторских прав ,
2. Синдицированный контент
Синдицированный контент - это контент, опубликованный на другом веб-сайте с разрешения автора оригинальной статьи. И хотя это законный способ представить свой контент новой аудитории, важно установить руководящие принципы для издателей, с которыми вы работаете, чтобы синдикация не превратилась в проблему SEO.
В идеале издатель должен использовать канонический тег на статье, чтобы указать, что ваш сайт является исходным источником контента. Другой вариант - использовать тег noindex для синдицированного контента. Всегда лучше проверять это вручную, когда синдицированный фрагмент вашего контента запускается на другом сайте.
3. HTTP и HTTPS страницы
Одной из наиболее распространенных проблем внутреннего дублирования являются идентичные URL-адреса HTTP и HTTPS на сайте. Эти проблемы возникают, когда переход на HTTPS не реализован с тщательным вниманием, которое требует процесс. Два наиболее распространенных сценария, когда это происходит:
1. Часть вашего сайта HTTPS и использует относительные URL. Часто справедливо использовать одну защищенную страницу или каталог (например, страницы входа в систему и корзины покупок) на HTTP-сайте, в противном случае. Однако важно помнить, что на этих страницах могут быть внутренние ссылки, указывающие на относительные URL-адреса, а не на абсолютные URL-адреса:
- Абсолютный URL: https://www.link-assistant.com//rank-tracker/
- Относительный URL: / rank-tracker /
Относительные URL не содержат информацию о протоколе; вместо этого они используют тот же протокол, что и родительская страница, на которой они находятся. Если поисковый бот найдет внутреннюю ссылку, подобную этой, и решит перейти по ней, он перейдет по URL-адресу HTTPS. Затем он может продолжить сканирование, перейдя по более относительным внутренним ссылкам, и даже может сканировать весь сайт в безопасном формате и, таким образом, проиндексировать две совершенно идентичные версии страниц вашего сайта. В этом случае вы хотите использовать абсолютные URL-адреса вместо относительных URL-адресов во внутренних ссылках. Если на вашем сайте уже есть дубликаты страниц HTTP и HTTPS, постоянное перенаправление защищенных страниц на правильные версии HTTP является лучшим решением.
2. Вы переключили весь свой сайт на HTTPS, но его версия HTTP все еще доступна. Это может произойти, если есть обратные ссылки с других сайтов, указывающие на страницы HTTP, или если некоторые внутренние ссылки на вашем сайте все еще содержат старый протокол, а незащищенные страницы не перенаправляют посетителей на защищенные. Чтобы избежать разбавления ссылочного сока и тратить свой бюджет на сканирование, используйте перенаправление 301 на все свои страницы HTTP и убедитесь, что все внутренние ссылки на вашем сайте указаны через относительные URL-адреса.
Вы можете быстро проверить, есть ли у вашего сайта проблема дублирования HTTP / HTTPS в SEO PowerSuite WebSite Auditor , Все, что вам нужно сделать, это создать проект для вашего сайта; когда приложение завершит сканирование, нажмите « Проблемы с версиями сайтов HTTP / HTTPS» в своем аудите сайтов, чтобы увидеть, где вы находитесь.
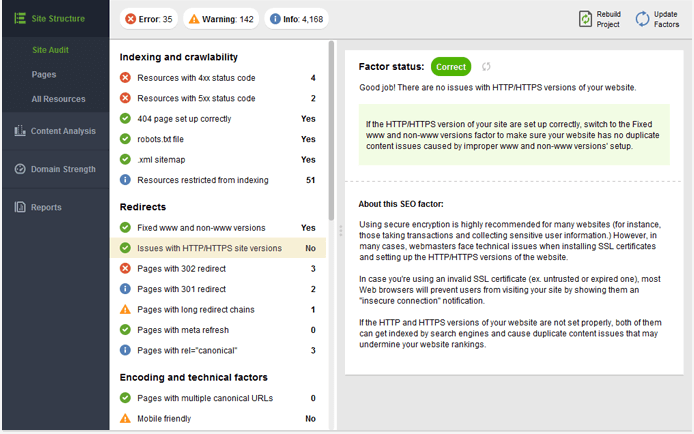
4. WWW и не WWW страницы
Одна из самых старых причин дублирования контента в книге - это когда доступны версии WWW и не WWW сайта. Как и в случае HTTPS, эта проблема обычно решается с помощью перенаправления 301. Возможно, еще лучшим вариантом является указание вашего предпочитаемый домен в консоли поиска Google.
Чтобы проверить, есть ли случаи такого дублирования на вашем сайте, посмотрите Исправленные версии www и версии без www (в разделе Перенаправления ) в вашем проекте WebSite Auditor.
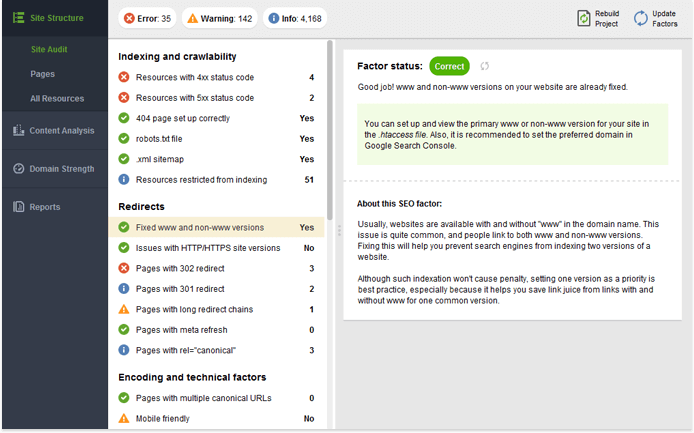
5. Динамически генерируемые параметры URL
Динамически сгенерированные параметры часто используются для хранения определенной информации о пользователях (например, идентификаторов сеансов) или для отображения немного другой версии той же страницы (например, с изменениями сортировки или фильтрации). Это приводит к URL-адресам, которые выглядят так:
- URL 1: https://www.link-assistant.com//rank-tracker.html?newuser=true
- URL 2: https://www.link-assistant.com//rank-tracker.html?order=desc
Хотя эти страницы, как правило, содержат одинаковое (или очень похожее) содержимое, обе они являются честной игрой для Google. Зачастую динамические параметры создают не две, а десятки разных версий URL, что может привести к значительным затратам на сканирование.
Чтобы проверить, является ли это проблемой на вашем сайте, перейдите на WebSite Auditor проект и нажмите Перестроить проект . На шаге 1 установите флажок Включить эксперт. На следующем шаге выберите Googlebot в параметре « Следуйте инструкциям robots.txt для…» .
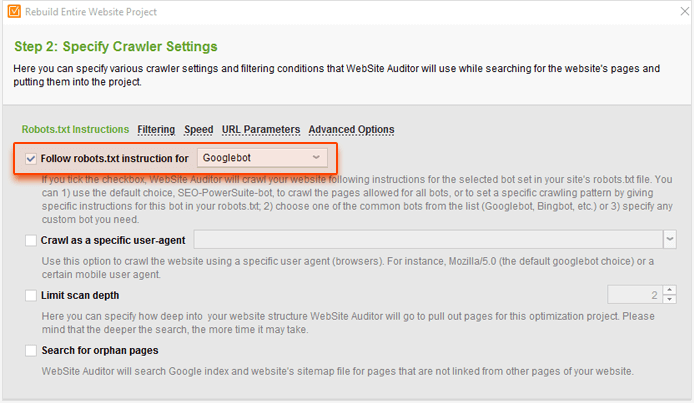
Затем перейдите на вкладку « Параметры URL » и снимите флажок « Игнорировать параметры URL» .
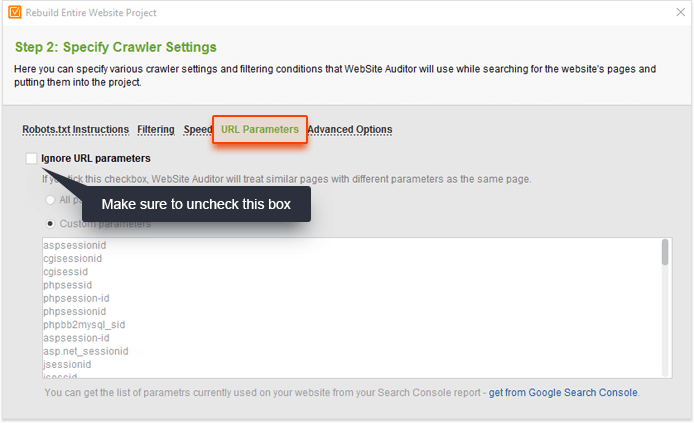
Эта настройка позволит вам сканировать ваш сайт, как Google (следуя инструкциям robots.txt для Googlebot), и обрабатывать URL-адреса с уникальными параметрами как отдельные страницы. Нажмите « Далее» и перейдите к следующим шагам, как обычно для запуска сканирования. Когда WebSite Auditor завершит сканирование, переключитесь на панель инструментов Pages и отсортируйте результаты по столбцу Page , щелкнув его заголовок. Это должно позволить вам легко обнаружить дубликаты страниц с параметрами в URL.
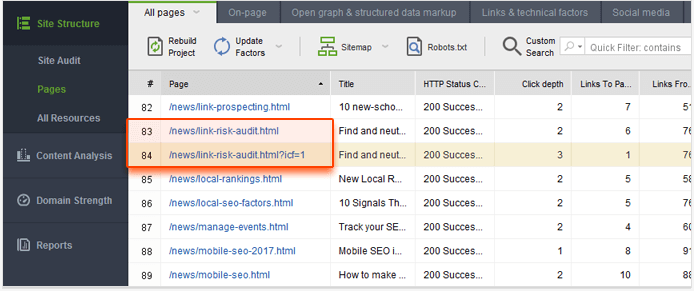
Если вы обнаружите такие проблемы на своем сайте, обязательно настройте управление параметрами в консоли поиска Google. Таким образом, вы будете сообщать Google, какой из параметров необходимо игнорировать во время сканирования.
6. Подобный контент
Когда люди говорят о дублировании контента, они часто подразумевают абсолютно идентичный контент. Тем не менее, части очень похожего контента также подпадают под Google определение дублированного контента:
«Если у вас много похожих страниц, рассмотрите возможность расширения каждой страницы или объединения страниц в одну. Например, если у вас есть туристический сайт с отдельными страницами для двух городов, но с одинаковой информацией на обеих страницах, вы можете объединить страниц на одну страницу об обоих городах, или вы можете расширить каждую страницу, чтобы содержать уникальный контент о каждом городе. "
Такие проблемы часто могут возникать на сайтах электронной коммерции с описаниями продуктов для аналогичных продуктов, которые отличаются только несколькими характеристиками. Чтобы решить эту проблему, постарайтесь сделать ваши страницы продукта разнообразными во всех областях, кроме описания: отзывы пользователей - отличный способ для достижения этой цели. В блогах похожие проблемы с контентом могут возникать, когда вы берете более старый фрагмент контента, добавляете некоторые обновления и переделываете его в новый пост. В этом случае наилучшим решением является использование канонической ссылки (или перенаправления 301) в более старой статье.
7. Страницы для печати
Если на страницах вашего сайта есть версии для печати, доступные по отдельным URL-адресам, Google будет легко находить и сканировать их по внутренним ссылкам. Очевидно, что содержимое самой страницы и ее версия для печати будет идентичным - таким образом, тратится ваш бюджет на сканирование еще раз.
Если вы предлагаете страницы для печати посетителям вашего сайта, лучше закрыть их из поисковых систем с помощью тега noindex. Если они все хранятся в одном каталоге, например https://www.link-assistant.com/news/print , вы также можете добавить правило запрета для всего каталога в вашем файле robots.txt.
Последние мысли
Дублированный контент может быть проблемой для SEO, так как он разбавляет сок ссылок на ваших страницах (он же ранжирование) и истощает бюджет сканирования, предотвращая сканирование и индексацию новых страниц. Помните, что ваши лучшие инструменты для борьбы с этой проблемой - это канонические теги, перенаправления 301 и robots.txt, а также включение проверок дублированного содержимого в процедуру аудита вашего сайта для улучшения индексации и ранжирования.
Какие случаи дублирования контента вы видели на своем собственном сайте, и какие методы вы используете для предотвращения дублирования? Я с нетерпением жду ваших мыслей и вопросов в комментариях ниже.
Html?Html?
Какие случаи дублирования контента вы видели на своем собственном сайте, и какие методы вы используете для предотвращения дублирования?

