- Однажды ...
- Говоря поисковой системе, что делать
- Как это работает?
- И может ли это действительно улучшить мое положение в поисковых системах?
- Эй, этот сайт, о котором вы рассказывали мне в предыдущей статье о HTML5, говорит, что почти ни один...
- заключение
- средство

Для неофитов данного предмета (среди которых я себя включаю) первое, что приходит на ум при прослушивании SEO, - это метатег и ключевое слово, и вскоре мы получаем (очень небольшое) разочарование, узнав, что мы действительно не знаем нет SEO
Однажды ...
Десять лет назад ключевые слова были первыми, что вы указывали при создании сайта, пока поисковым системам не надоело искать страницы с тысячами ключевых слов, которые не связаны друг с другом. Так что забудьте об этом, и ни одна поисковая система не учитывает ключевые слова. Не утруждайте себя этикеткой.
Но там не умер SEO, нет, не тесно. SEO - это наука, которая варьируется от правильного ведения ссылок сайта, чтобы сканеры (роботы, которые индексируют контент веб-сайтов) составляли полную карту, вплоть до неортодоксальных методов, таких как маскировка , показывающих другую страницу для сканера, который пользователь появляется в несвязанных поисках. Примером поразительной реальной технологии SEO было несколько лет назад, когда была организована кампания, в которой тысячи страниц содержали ссылку под названием «Мафия» и которая была направлена на сайт SGAE. Когда Google увидел, что существует так много сайтов, ссылающихся на этот сайт с этим словом, связь между этими двумя терминами увеличилась, так что при поиске «мафии» первым результатом был результат общества.
И, конечно же, после стольких лет, проведенных в Интернете, после долгих часов, потраченных на идеальную организацию контента ваших страниц, анализ статистики аналитика и, беспокоясь о том, что ваш сайт правильно продвигается в джунглях существующих социальных сетей (и я думаю, что половина в конечном итоге закроется излишком), вы в конечном итоге понимаете, что большая часть вашего успеха заключается в готовности Google к Захватите свой веб-сайт и выведите его в результаты поиска, когда это будет необходимо. И заключается в том, что Google не так совершенен, как мы иногда думаем, и мы должны прибегнуть к специализированным параметрам поисковой системы, чтобы найти результаты, которые должны были пройти, не прибегая к этому, и вместо этого мы нашли мусор.
Говоря поисковой системе, что делать
Что-то, что я люблю в HTML5 это абсолютный акцент на смысл того, что мы структурируем, как и должно быть. HTML используется, чтобы указать, какая часть контента у нас есть. Если у меня есть верхний колонтитул, статья и нижний колонтитул, то мне нужен верхний колонтитул , статья и нижний колонтитул , а не div, div и div. С HTML4 половина меток была разделителями, а другая половина была готова. По крайней мере, мы перестали использовать таблицы, чтобы разместить меню с одной стороны, а сообщения - с другой.
HTML служит для структурирования; чтобы определить стиль уже CSS , взаимодействовать и изменять отображаемый контент, JavaScript , и непреднамеренно получать вредоносное ПО через незащищенную уязвимость, подключаемый модуль Java (теперь серьезно: отключить его ).
К счастью, к типам WHATWG ( веб-гипертекста я не знаю, сколько я не знаю , аббревиатуру почти невозможно запомнить), отвечая за спецификацию, им пришло в голову добавить набор меток и атрибутов, специально разработанных для того, чтобы поисковые системы могли чтобы извлечь серию данных с нашего сайта: микроданные ( микроданные на английском языке). Разница с тем, что у нас было до сих пор, состоит в том, что вместо того, чтобы позволить поисковой системе идентифицировать информацию на странице своими собственными методами и решить, какой контент уместен, мы передадим ее себе.
Как это работает?
Ну, это очень просто. Представьте себе нашу типичную личную страницу, где у нас есть раздел, посвященный вам или вашему резюме, и у нас есть что-то такое, что:
<Раздел>
<p> <img src = "foto.png" alt = "Пепе Гарсия"> </ p>
<P>
Меня зовут Пепе Гарсия, я болгарский переводчик в EmpresasyMicrodatos SL
Мой электронный адрес: [email protected], а мой личный веб-сайт - http://pepegarciaempymic.com.
Я живу на улице Таль, Уэльва, Андалусия.
</ p>
</ section>
Ничего сложного. Если у нас это есть на нашем веб-сайте, поисковая система прочитает его и покажет в том виде, в котором оно отображается в результатах. Если мы посмотрим на контент, мы можем нарисовать несколько компонентов: собственное имя, фото, род занятий, где он работает, электронная почта, личная сеть и где он живет. В двух строках у нас много информации, которую Google сведет к простому абзацу, если мы не будем этого избегать.
Какие данные мы можем классифицировать с помощью микроданных? Люди, места, книги, фильмы, продукты ... очень много. Ответственные за проведение списка schema.org и если вы посмотрите немного, вы увидите, что существует множество различных сущностей, которые можно пометить десятками атрибутов. Мы собираемся использовать типы человек и почтовый адрес ,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<section itemscope itemtype = "http://schema.org/Person">
<p> <img itemprop = "image" src = "foto.png" alt = "Pepe Garcia"> </ p>
<P>
Меня зовут
<span itemprop = "name"> Пепе Гарсия </ span>, я
<span itemprop = "jobTitle"> Болгарский переводчик </ span> ru
<span itemprop = "affiliation"> EmpresasyMicrodatos SL </ span>
Мой адрес электронной почты
<span itemprop = "email"> [email protected] </ span> и мой личный веб-сайт
<span itemprop = "url"> http://pepegarciaempymic.com </ span>.
<section itemprop = "address" itemscope itemtype = "http://schema.org/PostalAddress">
Я живу в
<span itemprop = "streetAddress"> улица Тала </ span>,
<span itemprop = "addressLocality"> Уэльва </ span>,
<span itemprop = "addressRegion"> Андалусия </ span>.
</ section>
</ p>
</ section>
Я немного объясню, что мы сделали с кодом. Мы использовали три атрибута: itemscope , itemtype и itemprop . С помощью itemscope мы говорим, что внутренняя часть метки будет принадлежать области вид микроданных, а с помощью itemtype мы определяем тип анализируемого объекта: в нашем первом разделе - человек, а во втором разделе - почтовый адрес. С помощью itemprop мы определяем свойство.
Каждый раз, когда мы используем itemscope, мы должны использовать itemtype. И разве это не избыточно? То есть, если у нас уже есть тип элемента, мы уже знаем, что это тип микроданных, зачем нам нужен элемент? кто-то спросил это же в списках рассылки W3, и они ответили, что его было легче идентифицировать , Лично я не согласен.
И может ли это действительно улучшить мое положение в поисковых системах?
Это да! Давай попробуем У Google есть инструмент для тестирования структур данных этого типа, который называется Инструмент тестирования данных структуры Google , Если мы выберем вкладку HTML, мы представим наш код и дадим его для предварительной визуализации, мы получим:
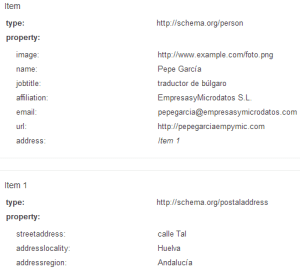
Данные извлечены Google из наших микроданных.
Одна из вещей, которую мы можем предварительно просмотреть на этой странице и которую Google может генерировать с помощью микроданных, - это так называемые Rich Snippets , которые я объясню с помощью изображения:

Жареная курица и микроданные
Это появляется, когда вы ищете "жареная курица" в Google. Что особенного в этом результате? Хорошо три вещи: четыре на пять звезд, 96 комментариев и 2 часа 40 минут, необходимых для приготовления курицы.
Откуда Google все это знает? Ну, один из двух, или нанял опытного шеф-повара для анализа результатов поиска, или кто-то использует микроданные. В этом конкретном случае они используют тип aggregateRating для оценок со свойствами ratingValue (оценка) и reviewCount (количество комментариев), и они также используют тип рецепт чтобы детализировать курицу и общее свойство time для времени приготовления.
Если вы зайдете в Интернет и посмотрите на исходный код, то увидите, что они использовали itemprop пятьдесят раз. Если кто-то отправляется в Google в поисках рецепта и находит результат, который дает вам столько информации, даже не заходя на страницу, вполне возможно, что вы убедите пользователя войти.
Эй, этот сайт, о котором вы рассказывали мне в предыдущей статье о HTML5, говорит, что почти ни один браузер не поддерживает эти микроданные ...
Эффективно. Если вы идете в HTML5Test Вы увидите, что ни Chrome, ни Safari, ни Internet Explorer (что удивительно) еще не внедрили микроданные. Что это значит? Ну ничего на самом деле.
Микроданные - это чисто семантические теги, они не имеют технической ценности. Ваш браузер не нуждается в них вообще, поисковая система делает это. Разница между браузером, который его поддерживает, и тем, что не в том, что движок, который его поддерживает, анализируя код и находя микроданные, скажет: «микроданные, я знаю, что это такое, не помогает мне, игнорирую», и браузер, который его не реализует, скажет: «микроданные, не знаю, что это такое, игнорируйте». Google, Bing и Yahoo! Они используют микроданные, чтобы показать результаты.
заключение
Для тех, кто уделяет большое внимание позиционированию в поисковых системах, микроданные являются важным инструментом.
Все, что нам пришлось использовать все эти годы для продвижения нашего веб-сайта, от изучения клиентов, социальных сетей , SEM , структурирования веб-сайтов, аналитики, AdWords, мета-тегов и т. Д., Которые Наконец, у нас есть прямой инструмент в нашем собственном коде, который дает вам информацию, которую поисковая система желает найти, и было бы реальной тратой не извлечь из нее максимальную пользу.
средство
Следующие две вкладки изменяют содержимое ниже.
У меня было свободное время, пока я не увлекся европейскими проектами. Инженер и инструктор, иногда одновременно, иногда отдельно. borjavmunoz (at) inerciadigital.com
И может ли это действительно улучшить мое положение в поисковых системах?Что такое SEO?
Как это работает?
Какие данные мы можем классифицировать с помощью микроданных?
И разве это не избыточно?
То есть, если у нас уже есть тип элемента, мы уже знаем, что это тип микроданных, зачем нам нужен элемент?
И может ли это действительно улучшить мое положение в поисковых системах?
Что особенного в этом результате?
Откуда Google все это знает?
Что это значит?

