- Ознайомтеся з нашим тестом "Канонічні теги через GTM" з минулого року
- Налаштування нашого нового тесту після введення-виведення
- Очікування результатів
- Google починає канонізувати наші тестові URL-адреси
- "Fetch and render> Request indexing" в GSC, здається, не прискорює ситуацію
- Новий звіт про покриття індексу консолі пошуку не говорить всю правду
- TL; DR
На I / O 2018, Джон Мюллер і Том Грінуей з Google дали відмінну презентацію про SEO для веб-сайтів JavaScript. Під час розмови Том Грінуей згадав, що Google не шукає канонічних тегів у візуалізованому HTML сторінки. Джон Мюллер пізніше кілька разів підтвердив цю заяву в Twitter. Оголошення викликало наше цікавість, оскільки ми раніше проводили тести, які змусили нас повірити, що канонічні теги вводяться за допомогою JavaScript за допомогою DID роботи Google Tag Manager. Ми вирішили створити новий тест після оголошення I / O. Ось результати.
Зауважте, що цей експеримент не стосується того, чи слід використовувати GTM або JavaScript для вставки критичних елементів у сторінку. Проблема, з якою звертається цей тест, полягає в тому, як Google має справу з веб-сайтами, що залежать від JavaScript на стороні клієнта, що є надзвичайно важливим питанням у день і вік популярних фреймворків JavaScript.
Поспіхом? Перейти прямо до Розділ TL; DR !
Ознайомтеся з нашим тестом "Канонічні теги через GTM" з минулого року
Оголошення Google здивувало нас, як наші попередні тести припустив, що канонічні теги та інші SEO-відповідні елементи завжди витягувалися з візуалізованого HTML, як тільки він був доступний, і більше не з вихідного документа HTML. Чи змінив Google спосіб роботи з канонічними тегами JS? Чи була наша інтерпретація попередніх результатів тесту неправильною?
Наші канонічний тег результату тесту з минулого року було засновано лише на одній URL-адресі, тому ми мали досить слабкі докази для підтвердження того, що Google використовує канонічні теги, які вводяться JS. Результатом нашого тестування може бути просто збіг обставин: Google, можливо, вирішив канонізувати нашу тестову URL-адресу до мети нашого JS-введеного канонічного тегу з інших причин.
Це є загальною проблемою при перевірці роботи канонічних тегів: чи можна використовувати канонічні теги лише між дуже подібними сторінками, які можуть бути канонізовані. Інакше ви ризикуєте повністю ігнорувати канонічні теги. З іншого боку, коли ваші сторінки з канонічними тегами канонізуються, ви не можете бути на 100% впевнені, що це дійсно пов'язано з канонічними тегами.
Примітка: Якщо ви думаєте “Чому вони просто не перевіряють нові звіти про покриття індексу GSC?”, Будь ласка, будьте терплячими і читайте далі. Потрапимо туди.
У минулому році ми ввели канонічну мітку на сторінку автора в англійській версії цього блогу, вказуючи на головну сторінку блогу. З тих пір сторінка автора була канонізована до головної сторінки блогу, яку можна перевірити за допомогою оператора info: search для URL-адреси в Google (знімок екрана від 11 травня 2018 року):
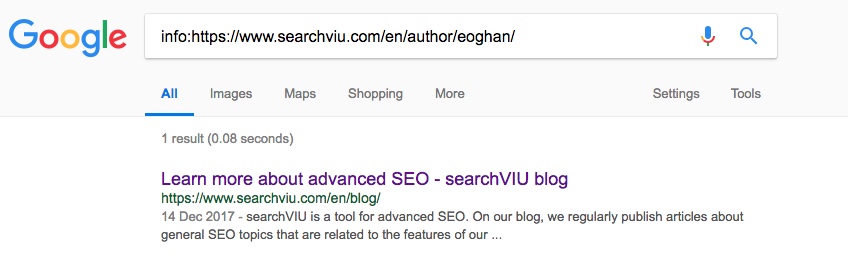
Канонізація відбулася після того, як ми ввели канонічний тег з JS за допомогою менеджера тегів Google, і жодна інша сторінка автора або категорії на нашому сайті ніколи не була канонізована аналогічно (з або без канонічних тегів JS). Чи було це просто збігом обставин?
Налаштування нашого нового тесту після введення-виведення
Після оголошення Google на I / O, ми хотіли повторити цей точний результат для більшої кількості URL, тому ми використовували JS і GTM, щоб вводити канонічні теги, що вказують на головну сторінку блогу на ще чотири сторінки категорій і авторів нашого блогу. Ми також переконалися, що залишимо дві подібні сторінки (мою сторінку автора автора й сторінку автора англійської мови Михайла) недоторканими, щоб мати контрольну групу URL-адрес, які не отримують жодних канонічних тегів, що вказують на інші сторінки, і тому не повинна бути канонізована Google. Якщо один з наших контрольних URL-адрес було канонізовано на головну сторінку блогу, не вводячи канонічний тег, це може означати, що тестові URL-адреси канонізувалися з інших причин, крім канонічних тегів JS.
Ось чотири нові тестові URL-адреси, для яких ми встановили канонічні теги JS 11 травня, через день після оголошення I / O від Google (всі знімки екрана зроблені 11 травня) .
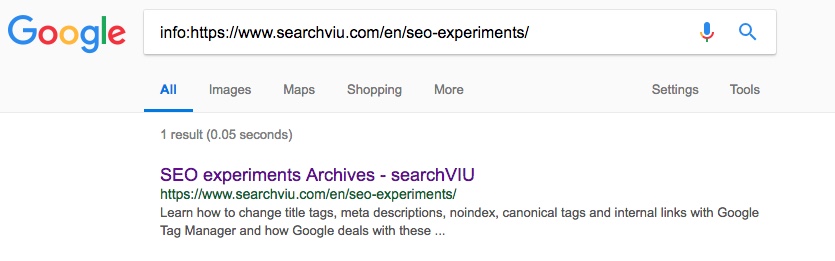
Англійська сторінка категорії "SEO експерименти":
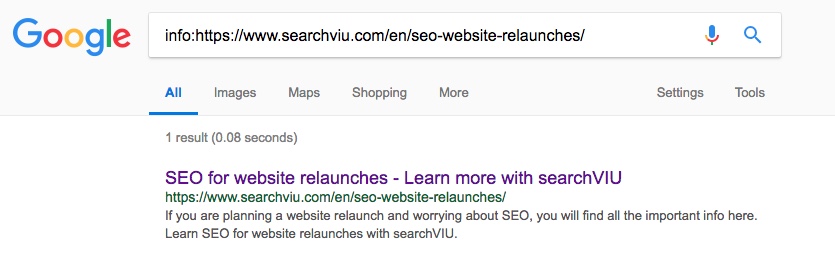
Сторінка категорії "SEO для перезапуску веб-сайту":
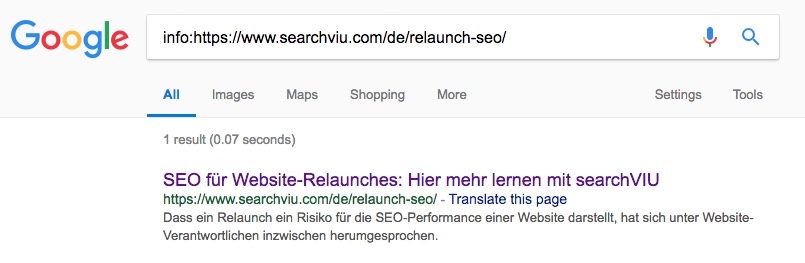
Сторінка категорії "SEO für Website-Relaunches":
Німецька авторська сторінка Майкла:
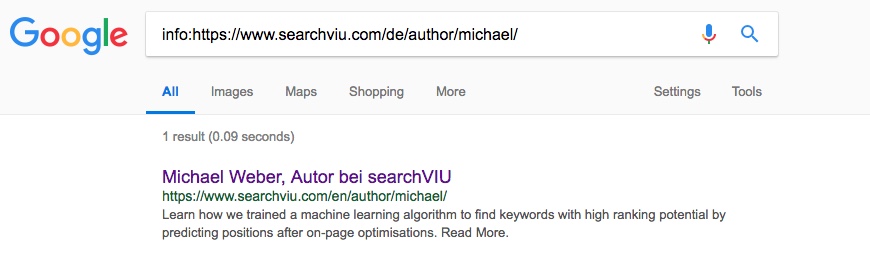
Зверніть увагу, що останній URL-адреса тесту вище, сторінка німецького автора Майкла, була канонізована на його сторінку автора англійської мови, коли ми встановлювали канонічний тег. На момент знімка екрана відсутні анотації hreflang, які тепер можна знайти на сторінці. Жодна з трьох інших сторінок не була канонізована під час скріншотів, і, наскільки нам відомо, вони ніколи не були канонізовані в будь-який час у минулому.
Очікування результатів
Після ін'єкції канонічних міток ми з нетерпінням чекали. З нашого досвіду роботи з попередніми тестами ми знали, що для цього потрібен час, оскільки такі зміни можуть тривати кілька місяців, поки вони не набудуть чинності. Це пов'язано з тим, що Google не рендерує сторінки так часто, як вони повторно сканують їх без рендеринга, і чим менш важлива сторінка, тим рідше вона повторно сканується, і навіть менш часто виводиться. Якщо ви ввели SEO-відповідний елемент, наприклад, канонічний тег, анотацію hreflang, або "noindex" у візуалізований HTML, але не включіть його у вихідний документ HTML, ви повинні бути готові довго чекати Ви бачите результати.
Google починає канонізувати наші тестові URL-адреси
Першою з наших тестових сторінок, які були канонізовані до мети нашого JS-введеного канонічного тегу, була наша сторінка категорії "SEO для веб-сайтів". Ми помітили цю зміну 21 травня, через 10 днів після ін'єкції канонічної мітки. Ось недавній знімок екрана відповідної інформації: результат оператора пошуку:
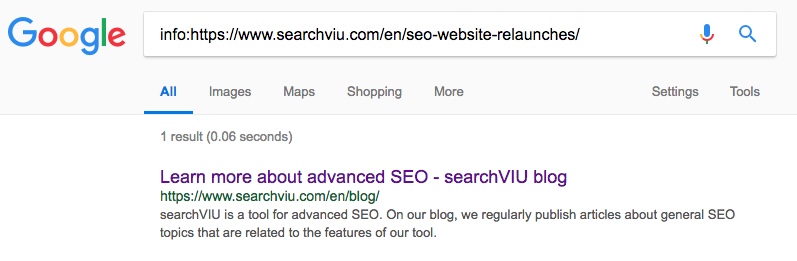
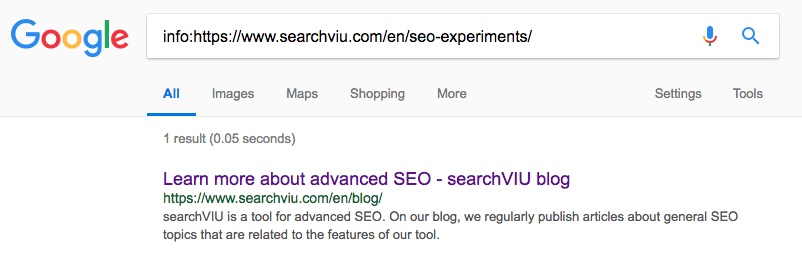
Далі, канонізовано англійську сторінку категорії «SEO експерименти». Це зайняло значно більше часу, і ми помітили зміни 3 червня, 23 дні після введення канонічного тегу:
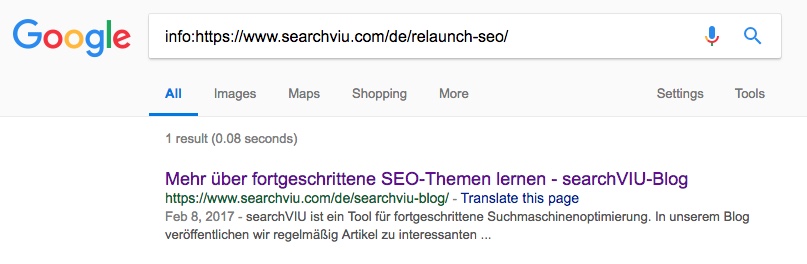
4 червня, через 24 дні після ін'єкції канонічного тегу з JavaScript, німецька сторінка категорії "SEO für Website-Relaunches" була канонізована на головну сторінку блогу нашої німецької версії сайту:
Наш четвертий тестовий URL, сторінка німецького автора Михайла, ще не була канонізована на момент написання (25 днів після ін'єкції канонічного тегу), але ми впевнені, що ця сторінка також буде канонізована до мети JS введений канонічний тег протягом наступного місяця:
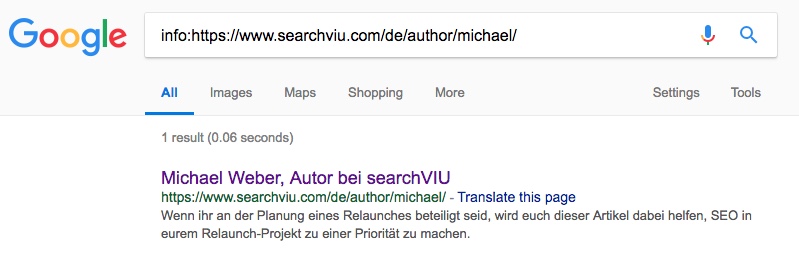
Оновлення (13 червня 2018 року): Ця URL-адреса тепер була канонізована, через 34 дні після введення канонічного тегу.
Дивлячись на ці дані, що ви думаєте? Чи є випадковість, що три з чотирьох тестових URL-адрес були канонізовані до цілей канонічних тегів, які ми вводили за допомогою JavaScript? Або Google все ще використовує канонічні теги JS, хоча офіційно заявили, що це не так? І якщо вони це роблять, то чому вони кажуть, що ні?
Перш ніж перейти до висновків, давайте поговоримо про деякі інші речі, які ви повинні знати про цей тест.
"Fetch and render> Request indexing" в GSC, здається, не прискорює ситуацію
Після ін'єкції канонічних тегів 11 травня ми виконали "Вибірка та візуалізація> Запитувати індексацію" для всіх наших тестових URL-адрес:
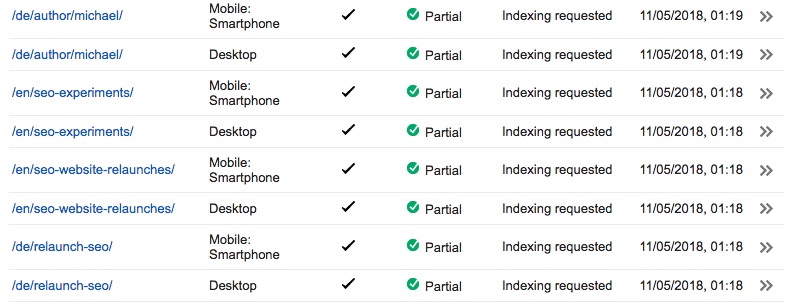
22 травня ми просили сканування та індексацію для наших основних сторінок блогу та всіх пов'язаних сторінок, оскільки всі наші тестові URL-адреси безпосередньо пов'язані з основних сторінок блогу. 1 червня ми виконали інший "Вибірка і рендеринг> Запросити індексацію" для трьох інших тестових URL-адрес, які не були канонізовані на цьому етапі.
Ми знаємо, що "Fetch and render> Request indexing" зазвичай має майже негайний ефект, коли ви використовуєте його для подання нової URL-адреси. Здається, це не впливає на рендеринг сторінки, або, принаймні, не завжди. Наш запит від 1 червня, можливо, ініціював канонізацію двох наших тестових URL-адрес 3-го і 4-го червня, але той 11 травня, звичайно, не мав негайного ефекту. Іншим фактором може бути те, що Google має виводити сторінку більше одного разу, перш ніж він вирішить підібрати введений канонічний тег.
Новий звіт про покриття індексу консолі пошуку не говорить всю правду
На момент написання цієї тестової URL-адреси минулого року та нашої нової тестової URL-адреси, яка була канонізована 21 травня, відображається як "Відправлена URL-адреса, не обрана як канонічна" у новому звіті про покриття індексу консолі пошуку Google:
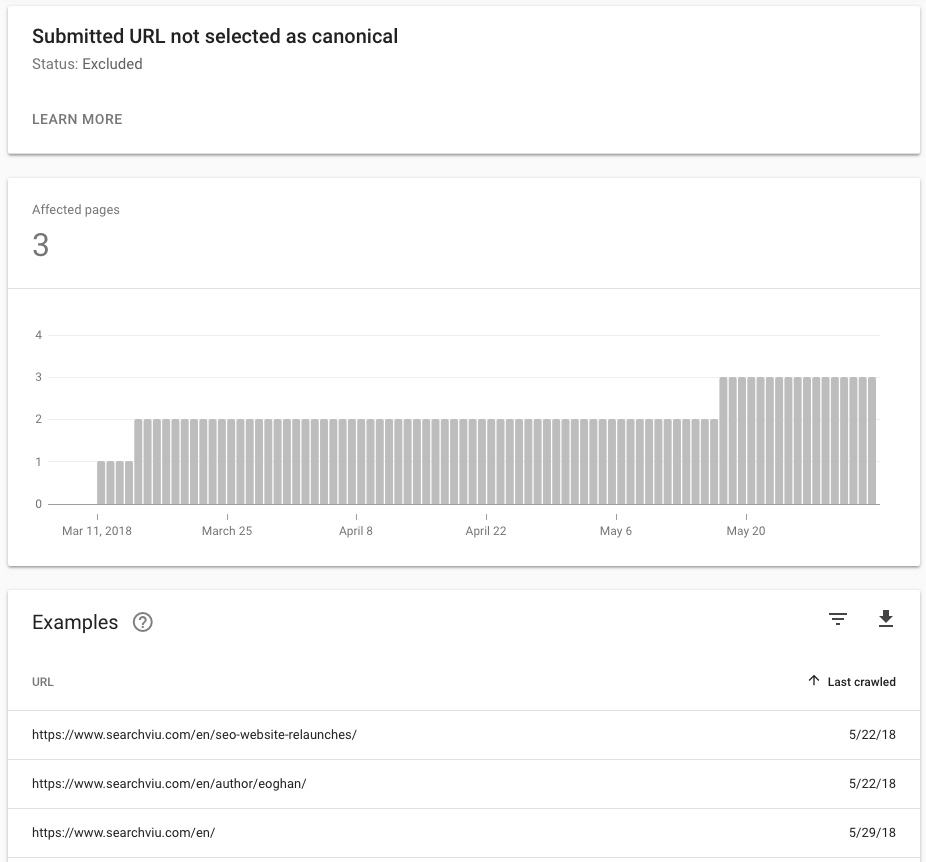
Два тестові URL-адреси, які були канонізовані 3 та 4 червня, все ще відображаються як "Відправлені та проіндексовані", оскільки дані, які GSC показують, не є актуальними, але я очікую, що вони відображатимуться як "Не надіслано URL як канонічний ”протягом наступних декількох днів.
Коли Google знаходить канонічний тег на сторінці і поважає її, ми очікуємо, що статус URL-адреси в новому звіті індексу буде "Альтернативна сторінка з правильним канонічним тегом". Що тут відбувається?
У мене є проста теорія, щоб пояснити це: Доповідь індексу Google Search Console веде себе точно так, як Том Грінуей та Джон Мюллер оголосили на та після введення-виведення - він ігнорує канонічні теги, які не є у вихідному документі HTML. Таким чином, це відображає поведінку, яку Google офіційно повідомляє, замість того, що показують результати цього тесту.
Таким чином, у Пошуковій консолі Google міститься інформація про те, які URL-адреси індексуються, і в ньому є набір правил, які, як припускає, Google використовує для індексації. Потім він використовує цей набір правил для створення звітів. Коли набір правил, які GSC використовує для створення своїх звітів, відрізняється від правил, які Google фактично використовує для індексації, у звітах відображається неправдива інформація.
Здається, це стосується канонічних тегів JS: Google використовує їх для канонізації сторінок, але GSC вважає, що це не так. Ось чому ці URL-адреси позначаються як "Відправлена URL-адреса, не обрана як канонічна" замість "Альтернативна сторінка з належним канонічним тегом". І це може також пояснити, чому Джон Мюллер на 100% переконаний, що Google не використовує канонічні теги JS:
hundo-p.
- Джон О.о (▽ ≦) o. ☆ (@JohnMu) 11 травня 2018 року
Я впевнений, що Джон Мюллер точно знає, як працює GSC, і я також впевнений, що команда GSC хоче надати точну інформацію. Але якщо є непорозуміння в Google або просто помилка (JS-введені канонічні теги не повинні бути використані, але вони є), то навіть офіційні заяви і звіти від Google можуть бути неправильними.
TL; DR
- Нещодавно компанія Google оголосила, що канонічні теги не обробляються, якщо вони знаходяться лише в HTML, а не у вихідному документі HTML.
- Ми перевірили це, ввівши канонічні теги в чотири URL-адреси за допомогою GTM, і результати тестування свідчать, що Google використовує ці канонічні теги.
- Потрібен було більше трьох тижнів для того, щоб деякі з тестованих URL-адрес могли бути канонізовані до цілей канонічних тегів JS.
- Здається, функція "Вибірка та візуалізація> Запитувати індексацію" в Пошуковій консолі Google не сприяє прискоренню візуалізації сторінок.
- Новий звіт про покриття індексу в Пошуковій консолі Google ігнорує канонічні теги JS у своїх звітах і, таким чином, відповідає офіційним заявам Google.
- Причиною, чому Google зробив оголошення, що здається неправильним, може бути внутрішнє непорозуміння або помилка.
Обговорення
Я був би радий почути вашу думку про все це! Що я пропустив? Де я помиляюся? На жаль, наші коментарі до блогу в даний час відключені, поки нам не вдасться реалізувати рішення, яке відповідає стандартам GDPR (пробачте!). Давайте поговоримо Twitter або де завгодно!
Поспіхом?Чи змінив Google спосіб роботи з канонічними тегами JS?
Чи була наша інтерпретація попередніх результатів тесту неправильною?
Примітка: Якщо ви думаєте “Чому вони просто не перевіряють нові звіти про покриття індексу GSC?
Чи було це просто збігом обставин?
Дивлячись на ці дані, що ви думаєте?
Чи є випадковість, що три з чотирьох тестових URL-адрес були канонізовані до цілей канонічних тегів, які ми вводили за допомогою JavaScript?
Або Google все ще використовує канонічні теги JS, хоча офіційно заявили, що це не так?
І якщо вони це роблять, то чому вони кажуть, що ні?
Що тут відбувається?

